
[2025-08] IROS Challenge: Vision-Language Manipulation in Open Tabletop Environments
Note: To protect commercial confidentiality, public information is limited.
Project Overview
We are hosting the IROS 2025 Challenge with two tracks: Manipulation and Navigation. The Vision-Language Manipulation in Open Tabletop Environments challenge, featured at the IROS 2025 Workshop, has a submission deadline of September 30th. We warmly welcome all participants!
My Contribution
As the evaluation lead for the manipulation track, me and my partners:
- Developed the benchmark environment of Genmanip
- Built the system from scratch with InternUtopia
- Implemented evaluation protocols in InternManip
Environment Components
- Tasks
- 10 manipulation tasks with two categories:
- Seen (objects in training set)
- Unseen (novel objects)
- Evaluation datasets: Hugging Face
validation ├── IROS_C_V3_Aloha_seen │ ├── collect_three_glues/ │ ├── collect_two_alarm_clocks/ │ ├── collect_two_shoes/ │ ├── gather_three_teaboxes/ │ ├── make_sandwich/ │ ├── oil_painting_recognition/ │ ├── organize_colorful_cups/ │ ├── purchase_gift_box/ │ ├── put_drink_on_basket/ │ └── sort_waste/ └── IROS_C_V3_Aloha_unseen ├── collect_three_glues/ ├── collect_two_alarm_clocks/ ├── collect_two_shoes/ ├── gather_three_teaboxes/ ├── make_sandwich/ ├── oil_painting_recognition/ ├── organize_colorful_cups/ ├── purchase_gift_box/ ├── put_drink_on_basket/ └── sort_waste/
- 10 manipulation tasks with two categories:
- Scenarios
- 10 seen + 10 unseen scenarios per task
- USD files with metadata
- Randomly generated
validation ├── IROS_C_V3_Aloha_seen │ ├── collect_three_glues │ │ ├── 000 │ │ │ ├── meta_info.pkl │ │ │ ├── scene.usd │ │ │ └── SubUSDs -> ../SubUSDs │ │ ├── 001/ │ │ ├── 002/ │ │ ├── 003/ │ │ ├── 004/ │ │ ├── 005/ │ │ ├── 006/ │ │ ├── 007/ │ │ ├── 008/ │ │ ├── 009/ │ │ └── SubUSDs ...
- Robots
- Supported platforms:
- Franka Arm + Panda Gripper

- Franka Arm + Robotiq Gripper

- Aloha Dual-Arm Robot (used in competition)

- Franka Arm + Panda Gripper
- Supported platforms:
- Controllers
- Joint position control
- Inverse kinematics solver
- I/O specs: Docs
Observation Structure (take franka as an example)
observations: List[Dict] = [ { "robot": { "robot_pose": Tuple[array, array], # (position, oritention(quaternion: (w, x, y, z))) "joints_state": { "positions": array, # (9,) or (13,) -> panda or robotiq "velocities": array # (9,) or (13,) -> panda or robotiq }, "eef_pose": Tuple[array, array], # (position, oritention(quaternion: (w, x, y, z))) "sensors": { "realsense": { "rgb": array, # uint8 (480, 640, 3) "depth": array, # float32 (480, 640) }, "obs_camera": { "rgb": array, "depth": array, }, "obs_camera_2": { "rgb": array, "depth": array, }, }, "instruction": str, "metric": { "task_name": str, "episode_name": str, "episode_sr": int, "first_success_step": int, "episode_step": int }, "step": int, "render": bool } }, ... ]Action Space (take franka as an example)
You can use any of the following action data formats as inputActionFormat1:
List[float] # (9,) or (13,) -> panda or robotiqActionFormat2:
{ 'arm_action': List[float], # (7,) 'gripper_action': Union[List[float], int], # (2,) or (6,) -> panda or robotiq || -1 or 1 -> open or close }ActionFormat3:
{ 'eef_position': List[float], # (3,) -> (x, y, z) 'eef_orientation': List[float], # (4,) -> (quaternion: (w, x, y, z)) 'gripper_action': Union[List[float], int], # (2,) or (6,) -> panda or robotiq || -1 or 1 -> open or close } - Sensors
- Franka: Tabletop, Gripper-FPV, Rear
- Aloha: Center FPV, Left/Right Gripper
franka + panda: camera 1 franka + panda: camera 2 franka + panda: camera 3 Metrics
The primary evaluation metric used is success rate, which is defined in two forms:- Soft success: A task is considered partially successful if only a subset of subtasks is completed. The soft success rate is the proportion of tasks that meet this partial success criterion.
- Hard success: A stricter metric where a task is only considered successful if all subtasks are completed.
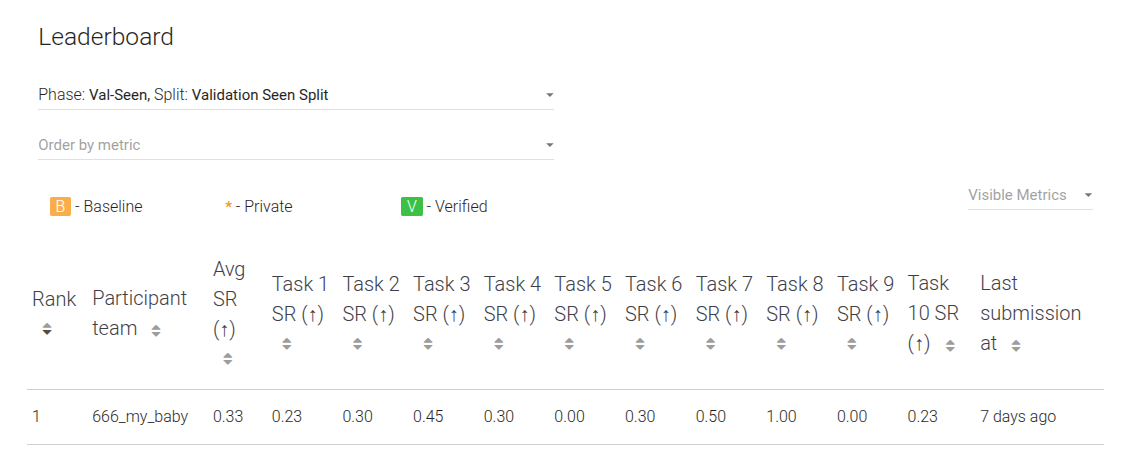
The baseline model used is the gr00t. The benchmarking results are shown below:

- Additional Components
- Developed a custom recorder to asynchronously capture frames and log both state and image data at each timestep, improving runtime efficiency.
- Implemented support for batch evaluation across multiple environments or parallel instances of Isaac Sim.
- A comprehensive list of configurable parameters and additional features can be found in the official documentation.
🔧 InternManip Integration
This evaluation environment is integrated as a benchmark module within InternManip. You can explore the implementation details under:
InternManip/internmanip/benchmarks/genmanip
While extending genmanip evaluation within InternManip, I implemented key components including:
- A wrapper environment
- A custom evaluator
- Parallel evaluation using the Ray framework
- Model and agent integration interfaces
Due to the ongoing development of InternManip, there are still many parts under optimization, so I am unable to showcase everything at this stage. However, once the IROS challenge concludes, a major refactor is planned.
🚀 What’s Next: Vision for InternManip
After the upcoming refactor, InternManip will evolve into a fully-fledged all-in-one training and evaluation framework for robotic manipulation tasks in simulation.
Key goals include:
- Rich set of algorithm implementations and benchmark examples
- User-friendly tools for training and evaluation
- Streamlined development workflow for algorithm researchers
This refactor will lay a solid foundation for future modular and scalable development. Stay tuned for the next release!